Description
Conversational Question Answering (ConvQA) involves multiple subtasks, i) to understand incomplete questions in their context, ii) to retrieve relevant information, and iii) to generate answers. This work presents PRAISE, a pipeline-based approach for ConvQA that trains LLM adapters for each of the three subtasks. As labeled training data for individual subtasks is unavailable in practice, PRAISE learns from its own generations using the final answering performance as feedback signal without human intervention and treats intermediate information, like relevant evidence, as weakly labeled data. We apply Direct Preference Optimization by contrasting successful and unsuccessful samples for each subtask. In our experiments, we show the effectiveness of this training paradigm: PRAISE shows improvements per subtask and achieves new state-of-the-art performance on a popular ConvQA benchmark, by gaining 15.5 percentage points increase in precision over baselines.
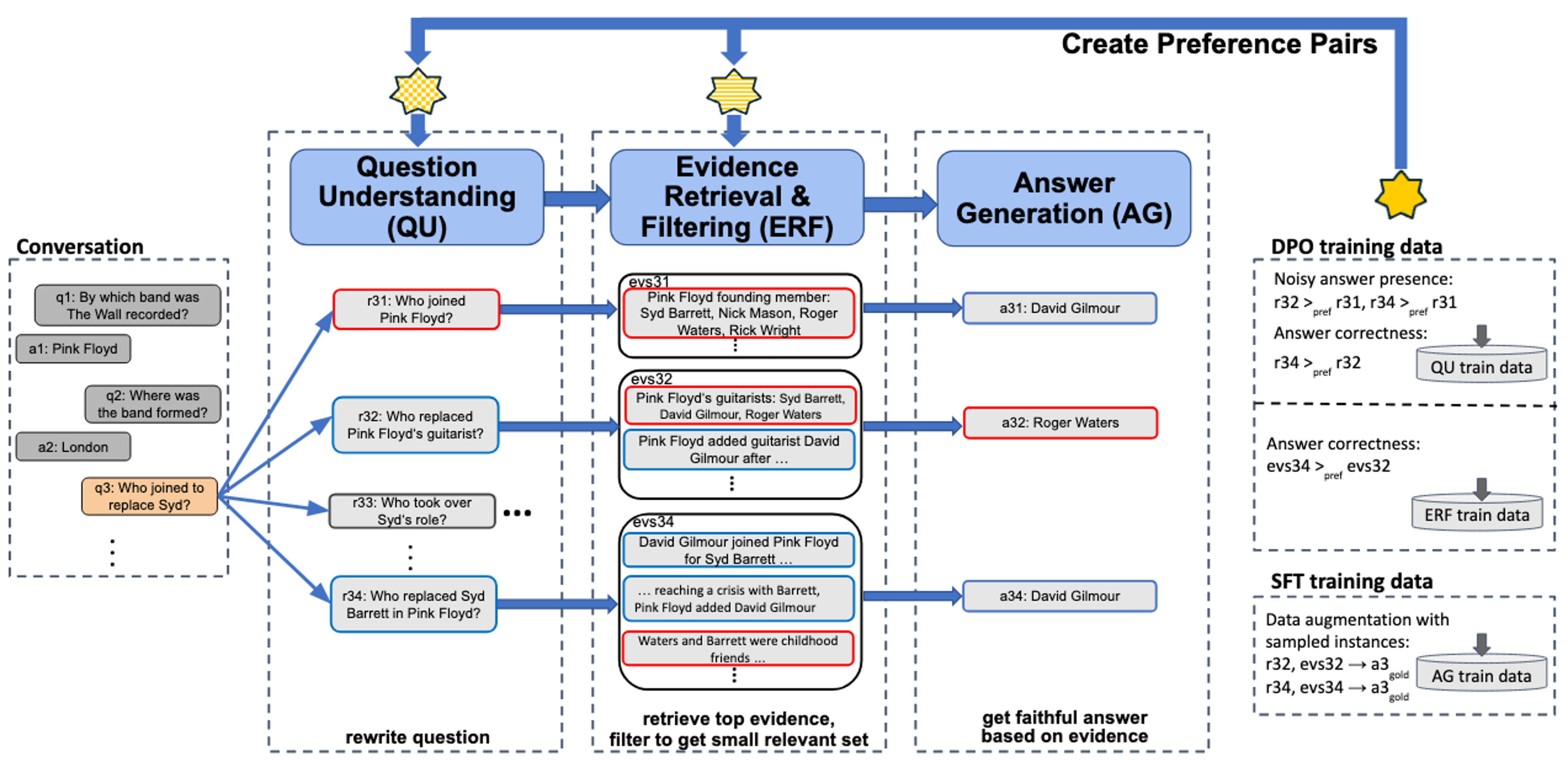
LLM-based Pipeline for ConvQA
Our method PRAISE (Preference-based Learning with Retrieval Augmented Iterative SEquence generation for ConvQA), is a pipeline architecture, consisting of question understanding (QU), evidence retrieval and filtering (ERF) and answer generation (AG). The figure above depicts these three stages, along with an example conversation. For each subtask, PRAISE samples generations from an initial model and learns from pairing successful and unsuccessful generations using Direct Preference Optimization (DPO). The intuition is that earlier tasks are optimized for later tasks via feedback signals without human intervention. Our QU model generates question reformulations so as to benefit the subsequent retrieval and answer generation. Question formulations are preferred that retrieve relevant evidence AND answer the question correctly and faithfully based on that evidence (like question formulation r34: Who replaced Syd Barrett in Pink Floyd? in the example). The retrieval step often yields long lists of potentially relevant evidence; feeding all these into the AG stage would incur high computational costs, if possible at all given the LLM’s limited context length. Therefore, the ERF stage of PRAISE contains a judiciously designed LLM-based evidence filtering technique, efficiently operating with subsets of evidence pieces. Evidence sets are preferred if they contain relevant question entities and the correct answer AND if they lead the AG model to generate the correct answer (like evidence set evs34 in the example). Finally, the AG stage is trained to give faithful answers with tangible evidence containing the answer and question cues (a34: David Gilmour in the example).
Code on GitHub
PRAISE codePaper
"Preference-based Learning with Retrieval Augmented Generation for Conversational Question Answering", Magdalena Kaiser and Gerhard Weikum, in Proceedings of the 2025 ACM Web Conference (WWW'25), Sydney, Australia, 28th April - 02nd May 2025. [Preprint] [Poster]Contact
For more information, please contact: Magdalena Kaiser (mkaiser AT mpi HYPHEN inf DOT mpg DOT de) or Gerhard Weikum (weikum AT mpi HYPHEN inf DOT mpg DOT de).
To know more about our group, please visit https://www.mpi-inf.mpg.de/departments/databases-and-information-systems/research/question-answering/.